A prize-winning ECR 2021 study of mammographic screening images has shown that automated analysis of breast positioning found a significant number of inadequate images in the technical repeats attributed to positioning errors.
"For technical repeat images, automated measurements related to inadequate visualization of the pectoral muscle on MLO (mediolateral) views represented the most common positioning deficiencies," noted Hannah Mary Gilroy, European innovation manager at Volpara Health, and colleagues. "Automated positioning measurement represents a promising means to continuously monitor image quality and radiographer performance in an objective manner."
In screening mammography, achieving good breast positioning is vital to ensure there is adequate tissue visualization. Research suggests that when image positioning quality fails to meet positioning criteria, the sensitivity of mammography can fall dramatically, but manually evaluating breast positioning is time-consuming and subjective, according to Gilroy and her team, who have received a magna cum laude award from the e-poster judges at ECR 2021.
The value of algorithms
Automated tools can improve the efficacy and lower the subjectivity of assessing breast positioning by providing objective and timely feedback on every image, the authors explained.
Algorithms help to ensure analysis is independent of a reader's training and experience by applying the same rules to every image. They can also identify trends and give regular feedback for continuous quality improvement, as well as providing timely analysis of positioning while the patient is in the room to aid the radiographer in deciding if a study is acceptable, and thereby avoid potential technical recall of the patient.
Emerging commercial offerings of automated positioning assessment tools require evaluation to provide evidence of measurement accuracy and of adequacy to reflect the desired evaluation scheme in the target setting, and the ultimate test is whether their implementation improves clinical practice, Gilroy and colleagues said.
The aim of the group's study was to provide first evidence of adequacy for an automated algorithm for scoring breast positioning, based on a so-called PGMI (perfect, good, moderate, inadequate) quality classification system, by investigating the association between technical repeats in the U.K. National Health Service Breast Screen Program (NHSBSP) and algorithm ratings.
The researchers retrospectively identified a dataset of four-view mammographic screening studies from the OPTIMAM image database (screening mammograms from two sites in the U.K. NHSBSP between 2011-2018) among women without findings (normal) for two or more screening rounds. They found 2,134 technical-repeat studies that included a single, same-day repeated view and reason codes related to inadequate positioning. There were 1,275 images with repeat code R1A (i.e., "Inadequate positioning -- Client") and 859 images with repeat code R1B (i.e., "Inadequate positioning -- Radiographer").
A second group of 1,340 "accepted" (no repeated views) studies were identified for comparison.
Logistics and main findings
The authors used Volpara Density and Volpara PGMI (Volpara Health Technologies) software to evaluate breast density and image-level breast positioning. A series of algorithms segments and identifies key landmarks in the breast, and using the identified landmarks, several breast measurements are made before assessing the positioning related to various metrics. The software then assigns image-level and study-level grades based on a combination of metrics.
Comparing the population statistics of the women who had technical repeats and women who had studies in which all images were accepted, the authors found no significant differences in age, volumetric breast density, breast volume, or compression.
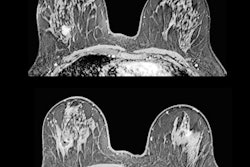
Distributions across the Volpara PGMI categories varied between the original views that were subsequently repeated and accepted images, with significantly fewer perfect (2% vs. 17%, p < 0.001) and more inadequate (41% vs. 2%, p < 0.001) scores in the original versus accepted groups, respectively.


Percentage of images scored as perfect, good, moderate, and inadequate by Volpara PGMI for original views, repeat views, and accepted views.
A significant (p < 0.001) reduction in inadequate scores was observed between the original (41%) versus repeat views (9%) of the technical repeat studies.
For original views, measurements related to inadequate visualization of the pectoral muscle on MLO views represented the most common positioning deficiencies. The original views had over four times more images in which the pectoral muscle failed to descend to within 1 cm of the posterior nipple line compared with the accepted images (70% vs. 15%, p < 0.001), and over three times more original views fail to be assessed as having adequate visualization of the pectoral muscle compared with the accepted images (48% vs. 14%, p < 0.001).


Percentage of mediolateral (MLO) and craniocaudal (CC) images that failed component metrics of Volpara PGMI software, including the following: if tissue has been cut off, whether or not the nipple was in profile, the difference in posterior nipple line (PNL) between CC and MLO of breast side, the adequacy of the pectoral muscle visualized (MLO only), if the pectoral muscle reaches the PNL (MLO only), the pectoral shape (MLO only), the presence of pectoral skinfolds, the visibility of the inframammary fold (MLO only), whether the nipple was pointing medially or laterally (CC only).
For CC views, there were significantly more original images in which the nipple was exaggerated from the central midline compared with accepted images (41% vs. 21%, p < 0.001). Pectoral shape was one metric for which the original views had a lower number of images that failed compared with the accepted images (36% vs. 48%, p < 0.001), according to Gilroy and colleagues.
Analysis of technical repeats
A review of the original views scored as perfect by Volpara PGMI showed most of these were due to the presence of other body parts obscuring tissue, or images in which the CC posterior nipple line reached to within 1 cm of the MLO PNL and passed but the repeat appears to have improved visualization of posterior tissue.
For 1,128 technical repeat studies, the image score was higher for the repeated view than the original view. For 850 technical repeat studies, the image score was the same for the original and repeated views. Many of these cases reflect the difficulty of positioning some women due to patient-related factors, the authors pointed out.
For 156 technical repeat studies, the image score was lower for the repeat view than the original view, indicating that the majority of those repeats that scored inadequate are partial or modified views and were likely acquired with the aim to improve visualization of particular areas of breast tissue.
According to the authors, "Most of these findings likely represent 'false negatives' and highlight the limitations of analysis without having a secondary review. However, we find it instructive that the study methodology revealed that cases may exist in which the repeat reason code may not have been accurately assigned and that this is one source of uncertainty for the interpretation of results."
A limitation of the study is that the cases collected were sourced from two screening centers and were predominantly carried out with Hologic equipment. Also, the images were reviewed independently of priors and clinical information, which is important information when deciding to repeat or not repeat an image. Further, the component metrics used to assess breast positioning did not include a metric related to other body parts creating obscuring artifacts in the image.
Future work
The authors are now planning a prospective study in which the automated software is used to provide feedback on breast positioning during the screening exam to measure the impact on technical repeats and technical recall rates.
"Future work could also include a retrospective analysis of repeated views by a panel of experienced radiographers and radiologists to confirm the need for repeat in the identified technical repeats," they noted. "For the current study, technical repeat cases with R1A and R1B codes were grouped for analysis, but a breakdown per category would be of interest to study the potential for different positioning deficiencies and likelihoods for their resolution between the groups."
Editor's note: The number of the ECR e-poster is C-13781, and you can access it via the EPOS section for the congress.