A multidisciplinary team from the Netherlands collected a top award at RSNA 2017 for identifying four key areas of future development for deep learning: multitask learning, image-to-image synthesis, unsupervised learning, and uncertainty estimation and novelty detection.
Ivana Išgum, PhD, and her colleagues at University Medical Center Utrecht received a prestigious magna cum laude prize for their e-poster presentation at the Chicago meeting.
Her team is focusing on the development of algorithms for quantitative analysis of medical images to enable automatic patient risk profiling and prognosis using techniques from the fields of image processing and machine learning. The group is looking at automatic cardiovascular risk assessment in CT- and MRI-based analysis of the developing neonatal brain, working with radiologists, genetics experts, and neonatologists.
 An example of a CT image derived from MRI using deep learning, with the real CT image aligned for reference (based on https://link.springer.com/chapter/10.1007/978-3-319-68127-6_2). The synthesized CT images closely match real reference CT images, potentially leading to a reduction in treatment planning time, patient discomfort, and CT radiation dose. This work was performed in collaboration with the radiotherapy department. All images courtesy of Jelmer Wolterink, PhD, and colleagues.
An example of a CT image derived from MRI using deep learning, with the real CT image aligned for reference (based on https://link.springer.com/chapter/10.1007/978-3-319-68127-6_2). The synthesized CT images closely match real reference CT images, potentially leading to a reduction in treatment planning time, patient discomfort, and CT radiation dose. This work was performed in collaboration with the radiotherapy department. All images courtesy of Jelmer Wolterink, PhD, and colleagues.Išgum, an associate professor and group leader of the Quantitative Medical Image Analysis (QIA) unit in the Image Sciences Institute, highlighted the following deep-learning topics for future investigation:
- Multitask learning. Current methods typically focus on a single task in a single modality, but one network may be used to perform different tasks, and this can raise efficiency because tasks share information about appearance and anatomy and lead to lower computational demands, she explained. For instance, a single-task network performing brain MRI segmentation can be trained to also perform cardiac CT and breast MR segmentation, achieving equivalent performance.
- Image-to-image synthesis. Images can be translated from one domain to another, e.g., synthesis of pseudo-CT images from brain MR and synthesis of routine-dose CT images from low-dose CT. Acquisition of certain images may be omitted to save time and reduce costs, patient discomfort, and CT radiation dose. The network can predict a Hounsfield unit value for each voxel in the MR image, and noise can be removed.
- Unsupervised learning. Current supervised deep-learning methods require training data that are well-structured and contain annotations, segmentations, or labels. Acquisition of labeled training data is a time-consuming task, e.g., manual segmentation of brain MRI can take up to 40 hours. Millions of medical images without annotations are readily available. In unsupervised learning, such data without annotations can be used. Potential applications include combining image data with unstructured reports to identify clusters of patients, phenotyping patients for heart failure based on ultrasound, and synthesizing diverse images from noise using generative adversarial networks, according to Išgum and colleagues.
- Uncertainty estimation and novelty detection. A deep-learning model will always predict something, but how can we be sure that what it's predicting is correct? How "sure" is the model of its decision? And what should a model do when it sees something unfamiliar? Answering such questions is crucial for clinical applications and clinical acceptance, and to address them, future research may focus on the estimation of uncertainty and detection of novelty.
Effective use of artificial neural networks
Deep-learning models are data processing systems that transform inputs into outputs, the authors stated. In medical applications, the input is usually an image, and the output that the model gives depends on the task that it is trained for; it can consist of one or multiple outputs.
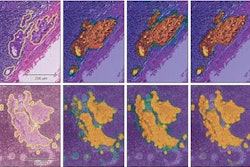
 This figure shows an abstraction of work done on multitask learning for brain MR segmentation, cardiac CT segmentation, and breast MR segmentation (based on https://link.springer.com/chapter/10.1007/978-3-319-46723-8_55). The authors found that training a network to jointly perform these tasks did not affect its performance on any individual task. This may be a stepping stone toward a single system that can perform multiple tasks in medical image analysis.
This figure shows an abstraction of work done on multitask learning for brain MR segmentation, cardiac CT segmentation, and breast MR segmentation (based on https://link.springer.com/chapter/10.1007/978-3-319-46723-8_55). The authors found that training a network to jointly perform these tasks did not affect its performance on any individual task. This may be a stepping stone toward a single system that can perform multiple tasks in medical image analysis.Deep-learning methods use artificial neural networks (ANNs), which consist of interconnected cells, similar to neurons. The cells are connected by weights, whose value can be changed. Various components are stacked to form multilayer ANNs. Subsequent layers combine and analyze the output of previous layers, adding more abstraction. Furthermore, convolutional filters analyze small regions of the image in a sliding window fashion, downsampling layers compress and filter information, and dense layers combine all information.
"The exact composition of building blocks in a network is task-specific," the authors noted.
Most ANNs are optimized to minimize an error with respect to reference values, i.e., supervised learning. In the so-called forward pass, the network is applied to the input to predict an output, while in the backward pass, network parameters are updated to minimize the prediction error. A network is trained with many iterations of the forward and backward passes, and each iteration uses a small selection, or minibatch, of input samples and labels.
In radiology reports, deep learning can be used to generate sequences of words, such as automatic image captioning. The technology can be adapted to generate reports from medical images. Deep-learning methods currently are used to analyze a wide range of imaging modalities and anatomical structures. They have the potential to be applied to all analysis steps between image acquisition and report generation, but typically they require annotated data for training.
"In the near future, we may see deep-learning methods combining learning for multiple modalities and structures, synthesizing realistic images to prevent unnecessary acquisitions, learning from large amounts of unstructured and unannotated data, [and] determining the certainty of deep-learning models," they predicted.
The prizewinning RSNA poster can be viewed via this Google Doc from the authors, who also urge everybody to visit their website.