A hybrid reading strategy for screening mammography using AI and radiologists showed success in a study published on 19 August in Radiology.
A team led by doctoral candidate Sarah Verboom from Radboud University Medical Center in Nijmegen, the Netherlands, found that its model reduced radiologist workload by 38% without changing recall or cancer detection rates.
“What we saw is that there was some overlap with what radiologists find difficult,” Verboom told AuntMinnieEurope. “So, we saw with the exams that AI was more uncertain about, radiologists also made more mistakes. But what was very surprising was that we didn’t see any differences in cancer types.”
While high-performing AI models can detect breast cancer with great accuracy, they still miss some cancers. This makes finding exams where AI is unreliable important, where human interpretation is needed. The researchers highlighted a lack of data evaluating the best strategy for using uncertainty estimation on best practices for AI-based breast cancer detection models in screening.
Verboom and colleagues developed a hybrid reading approach that uses a combination of radiologists and a standalone AI model (ScreenPoint Medical) to interpret cases in which the AI model performs as well as or better than the radiologist. The AI model made recall decisions only when predictions were deemed confident. Radiologists performed double reading in cases where the AI model was unsure of its findings.
They used a dataset of 41,469 screening mammograms collected between 2003 and 2018 from 15,522 women with a median age of 59 years. This included 332 screen-detected cancers and 34 interval cancers. The exams were performed as part of the Dutch National Breast Cancer Screening Program.
The researchers divided the dataset at the patient level into two equal groups with identical cancer detection, recall, and interval cancer rates. They determined the best thresholds for the hybrid reading strategy in the first patient group, while using the second group to evaluate the reading strategies.
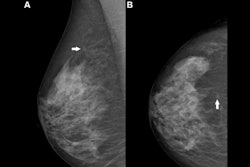
 The only example of a screening exam with a screen-detected cancer that would have been missed by AI in a hybrid reading strategy based on the AI uncertainty score of the entropy of the mean probability of malignancy (PoM) score of the most suspicious region. During screening, a 52-year-old woman was recalled following arbitration scoring of the right breast as Breast Imaging Reporting and Data System (BI-RADS) 4 after the first and second radiologists scored the right breast as BI-RADS 1 and 4, respectively. This woman would not have been recalled if the examination was read by the AI model, which assigned a PoM score of 30, which would be classified as a certain prediction with an uncertainty quantification of 0.57. Both the mediolateral oblique (left) and craniocaudal (right) views of the affected breast are shown. The boxes indicate the calcifications found during screening, and the final diagnosis of this examination was ductal carcinoma in situ.RSNA
The only example of a screening exam with a screen-detected cancer that would have been missed by AI in a hybrid reading strategy based on the AI uncertainty score of the entropy of the mean probability of malignancy (PoM) score of the most suspicious region. During screening, a 52-year-old woman was recalled following arbitration scoring of the right breast as Breast Imaging Reporting and Data System (BI-RADS) 4 after the first and second radiologists scored the right breast as BI-RADS 1 and 4, respectively. This woman would not have been recalled if the examination was read by the AI model, which assigned a PoM score of 30, which would be classified as a certain prediction with an uncertainty quantification of 0.57. Both the mediolateral oblique (left) and craniocaudal (right) views of the affected breast are shown. The boxes indicate the calcifications found during screening, and the final diagnosis of this examination was ductal carcinoma in situ.RSNA
Using the best-performing uncertainty metric, which was the entropy of the average probability of malignancy of one region, 61.9% of the breast exams were read by radiologists.
Hybrid reading led to a recall rate of 23.6% and a cancer detection rate of 6.6%. To compare, standard double reading led to a 23.9% recall rate and a 6.6% cancer detection rate (p = 0.14).
The model, meanwhile, achieved an area under the curve (AUC) of 0.87 for exams with uncertain projections and 0.96 for exams with certain projections (p = 0.02).
Verboom said that with these results in mind, commercial AI models should include metrics of uncertainty to improve the performance of and trust in the models to create more accurate diagnoses. She also told AuntMinnieEurope that the researchers are planning a prospective study with their approach.
Sarah Verboom explains how results from the new study add to the discussion of AI's potential role in breast imaging.
The “real innovation” of the research is its proposed framework that acknowledges AI’s potential and limits, according to an accompanying editorial written by Prof. Pascal Baltzer, from the Medical University of Vienna in Austria.
“The AI tool is not used indiscriminately. Instead, it contributes when helpful and steps back when appropriate,” Baltzer wrote. “In this study, AI identified that about four in every 10 cases did not require a second look -- cases where the algorithmic output was consistently accurate. That’s practical, data-informed triage that connects with clinical reality.”
The full study can be found here.